Structured documents are what make agent-assisted work possible
When teaching materials live in readable, structured formats, agents can do what would otherwise require sustained manual attention: checking claims against the literature, auditing accessibility across every slide, applying changes uniformly across an entire module. Binary formats like PowerPoint make this impossible.
I’ve written my lecture slides in markdown for several years. The reasons were originally practical: one format, one place, no application lock-in, the ability to version-control a file rather than maintain a growing archive of differently-named copies. I used Obsidian’s Marp plugin to get a presentation preview alongside the source, and that was essentially the whole setup; simple, portable, and easy to maintain.
What I didn’t anticipate was what that choice would mean once I started using AI agents to prepare lecture slides. What started as a formatting preference turned out to be an infrastructure decision that determines not just how I maintain my teaching materials, but what kinds of work become possible.
The slide deck
The screenshot below shows what a slide deck looks like in Obsidian, using last year’s version of the lecture. This is a module in its fourth year of delivery; past the point of major redesign and into the phase where refinement is what matters. It’s worth keeping that in mind when you’re reading this post.
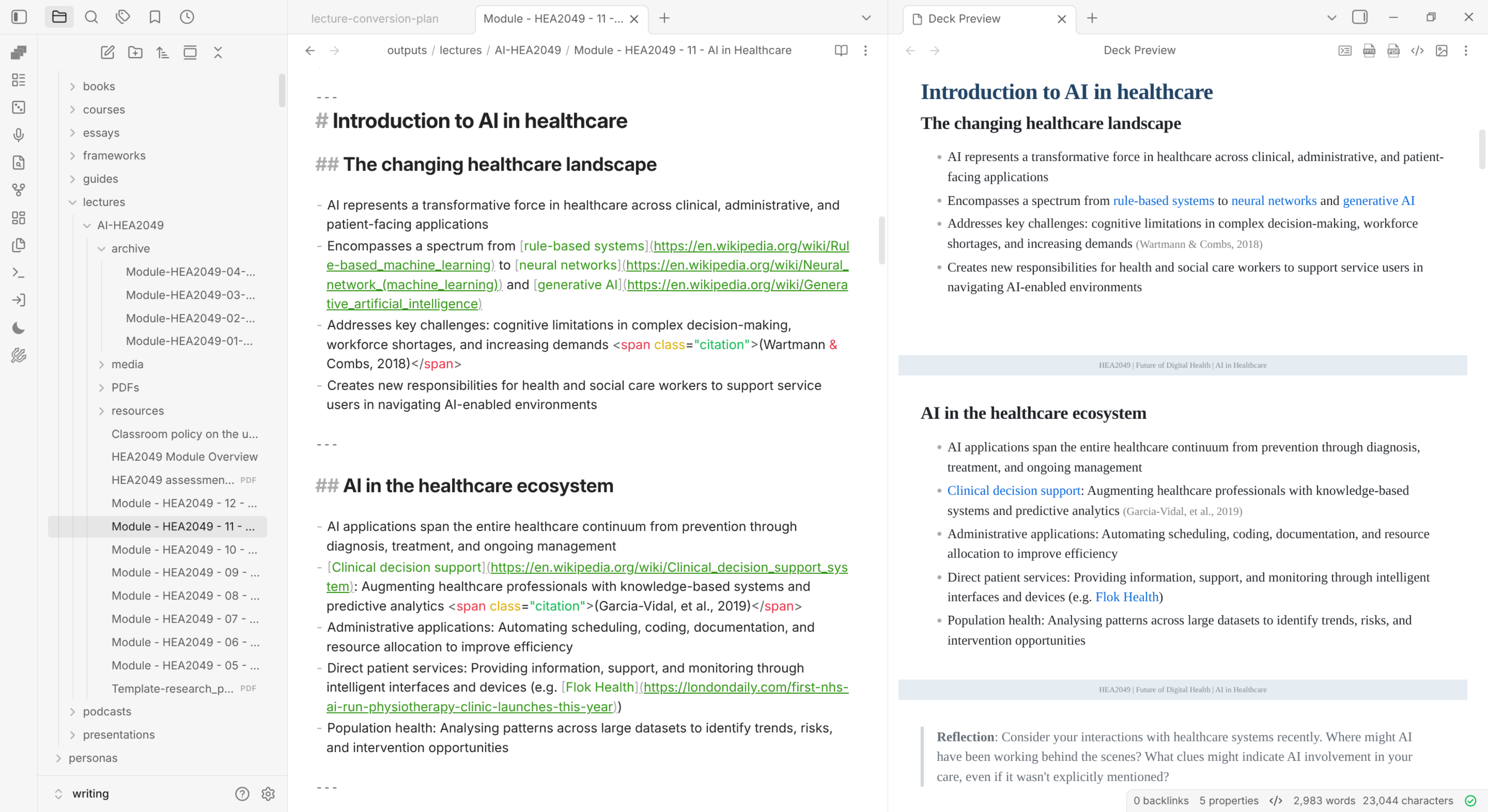 A single markdown file holds both the content and the metadata that Marp uses to determine how the slides look. The Marp plugin renders the markdown in real time, visible in the right panel.
A single markdown file holds both the content and the metadata that Marp uses to determine how the slides look. The Marp plugin renders the markdown in real time, visible in the right panel.
The content itself is just text: headings that become slide titles, bullet points, links to external content, inline citations formatted as <span class="citation"> spans. There is nothing here that any application capable of reading plain text cannot read.
And, of course, you can generate the outputs you need directly from the plugin, including HTML, PPT, PDF, and ePUB.
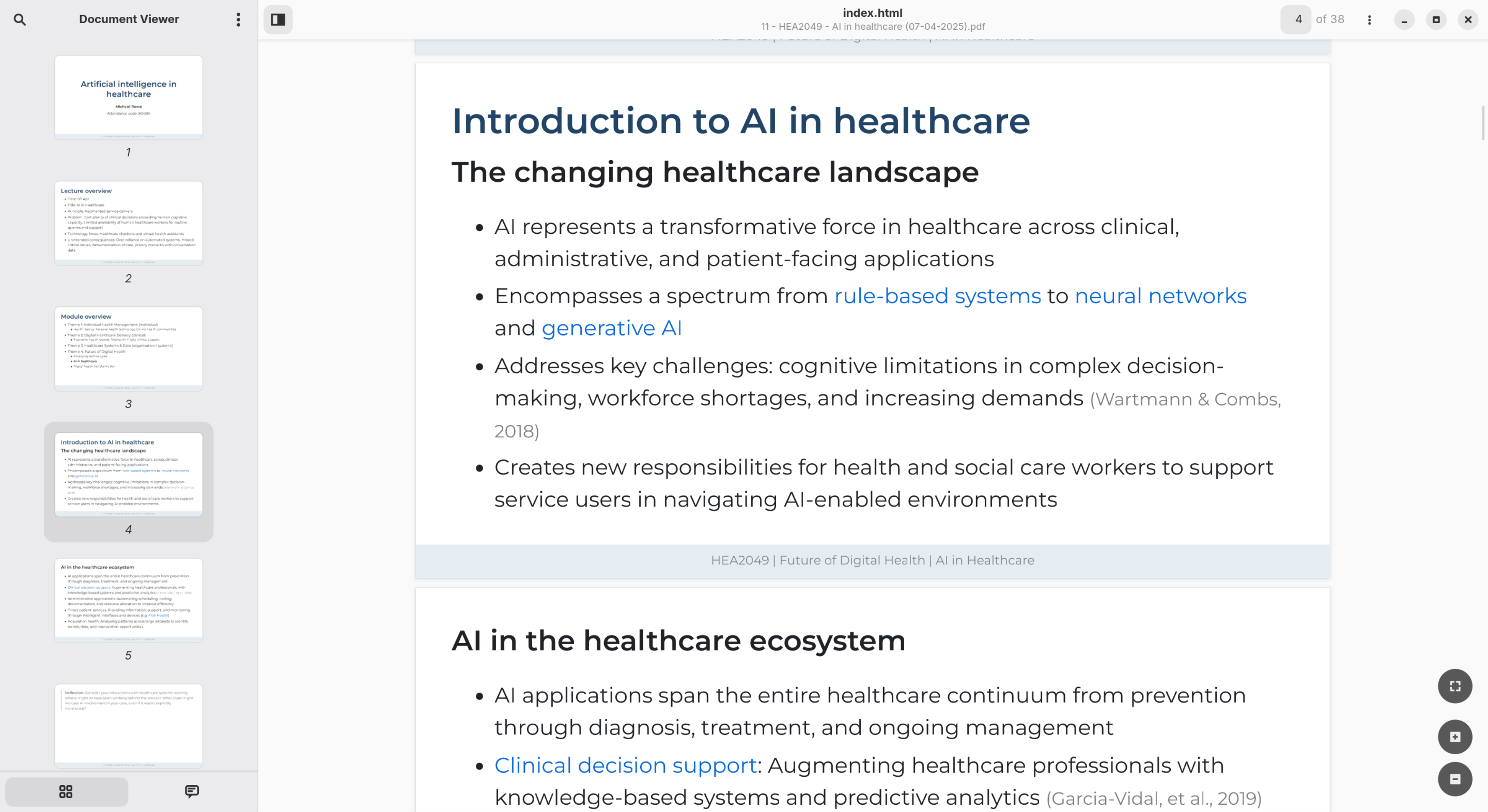 Obsidian uses the Marp plugin to generate PDF versions of the markdown-formatted slides.
Obsidian uses the Marp plugin to generate PDF versions of the markdown-formatted slides.
That’s a rough overview of how I’ve been managing things until recently. Now, I’m busy reviewing my slides for this year’s delivery and wanted to share a bit about how my process has changed since I’ve been using Claude Code. Feedback from the module evaluation was that the slides were too content-heavy, with too many new concepts introduced in each session, and not enough activity.
What an agent can do with a single file
This year’s review aims to act on feedback from the module evaluation — alongside my own reflections, and discussion with the programme team — and update the slides. Rather than working through each file manually, I set up a series of personas; structured instruction sets that define how the agent should approach specific aspects of the work. These include a classroom teacher, a slide designer, an AI literacy adviser, a reference manager, and an accessibility checker.
Each persona encodes a particular kind of expertise as a set of criteria the agent applies during the build. The slide-designer persona, for instance, doesn’t just format slides; it enforces design principles drawn from visual communication research:
Signal-to-noise ratio: Does every element on the slide carry meaning? Remove decorative borders, logos on every slide, clip art, and anything that does not advance the message.
The 3-second rule: If a slide cannot be understood in roughly 3 seconds, it is too complex. Simplify or split.
Slide citations: Whole-slide supporting citations appear as
<p class="citation">Author et al. (year)</p>at the bottom of the slide — right-aligned, light grey, small. Multiple sources separated by semicolons. […] If a suitable citation cannot be confirmed, flag it rather than fabricating one.
The accessibility checker is similarly specific, mapping Marp’s markdown syntax directly to Blackboard Ally’s WCAG 2.2 accessibility requirements:
Check Requirement Ally impact Tagged PDF PDF must have semantic tags for structure/navigation Critical — untagged = inaccessible Alt text All images must have descriptive alternative text Critical — missing = severe penalty Colour contrast Minimum 4.5:1 ratio for normal text, 3:1 for large text High — WCAG 2.2 AA requirement Language Document language must be set Medium Marp-specific standards: Alt text in Marp uses the
syntax — the text in square brackets is critical. Marp keywords in alt text (likebg,w:,h:) should not replace meaningful descriptions. One concept per slide is the single most impactful change for reducing cognitive load.
These aren’t suggestions the agent considers. They’re criteria it applies systematically to every slide it builds. PDFs generated through this process achieve perfect scores on Blackboard Ally’s accessibility checker, not because I carefully reviewed each slide against a checklist, but because the checklist is embedded in the build process itself.
The screenshot below shows an agent mid-task, working on a slide deck for AI in healthcare. The task list is visible in the terminal: several stages in progress simultaneously. But the detail I want to draw attention to is in the tool calls just above the task list: the agent has paused its build to run two searches against my Zotero library (I’m writing a separate post on how I’ve set up a local MCP server that uses the Zotero API to do this).
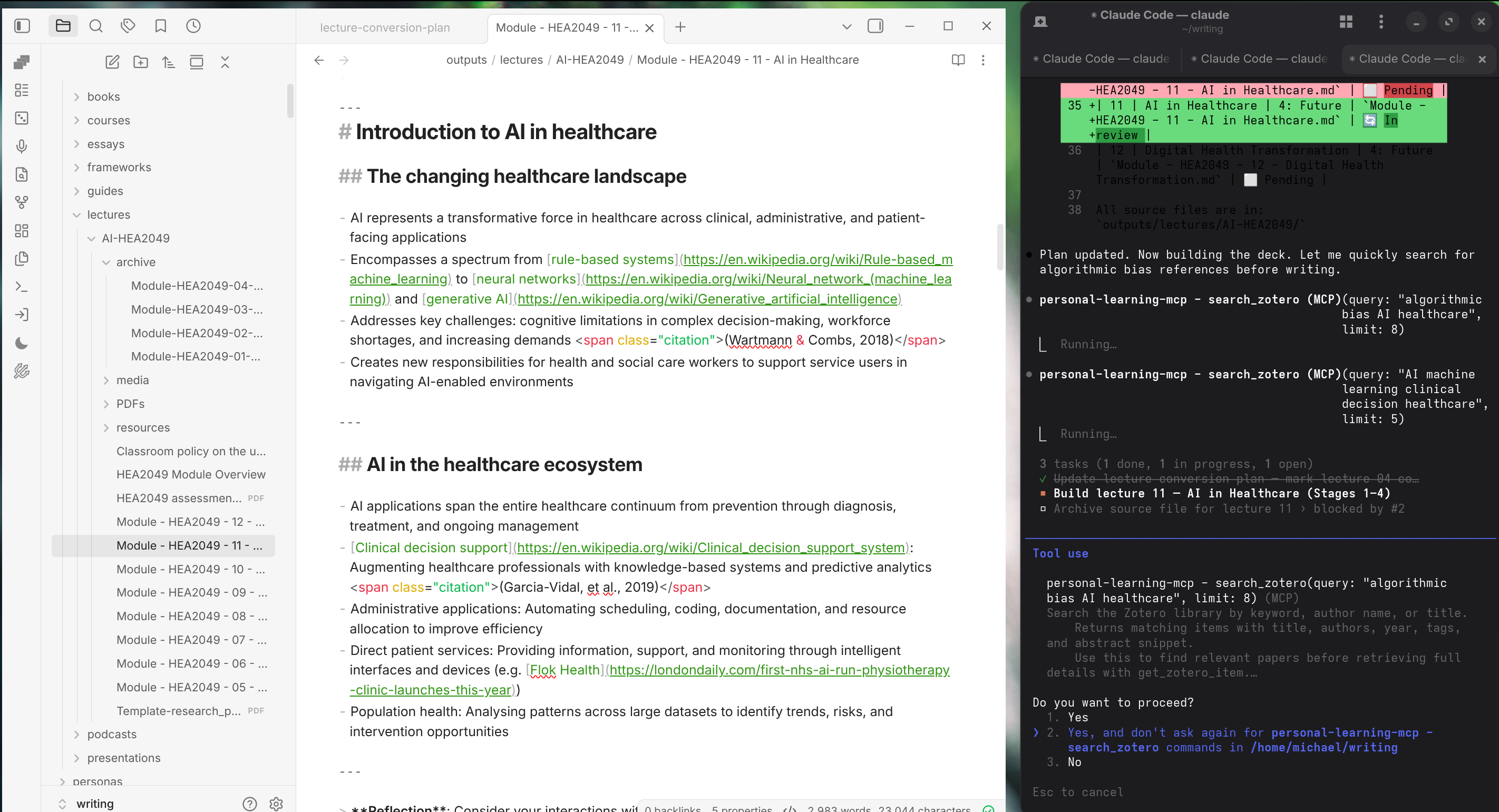 The agent searches the reference library mid-task, looking for papers on algorithmic bias in healthcare and clinical decision-making.
The agent searches the reference library mid-task, looking for papers on algorithmic bias in healthcare and clinical decision-making.
In this example, Claude Code wasn’t instructed to search Zotero. It identified claims in the slide content that required supporting references, noticed it had access to a Zotero search tool, and used it — returning papers I had already read and annotated, which it then inserted as inline citations at the appropriate slides. This is the kind of task that is easy to do poorly and tedious to do well: checking whether the claims in a lecture are properly grounded in the literature you have.
The completion summary tells the full story of what happened in the process of using multiple personas to update this slide deck:
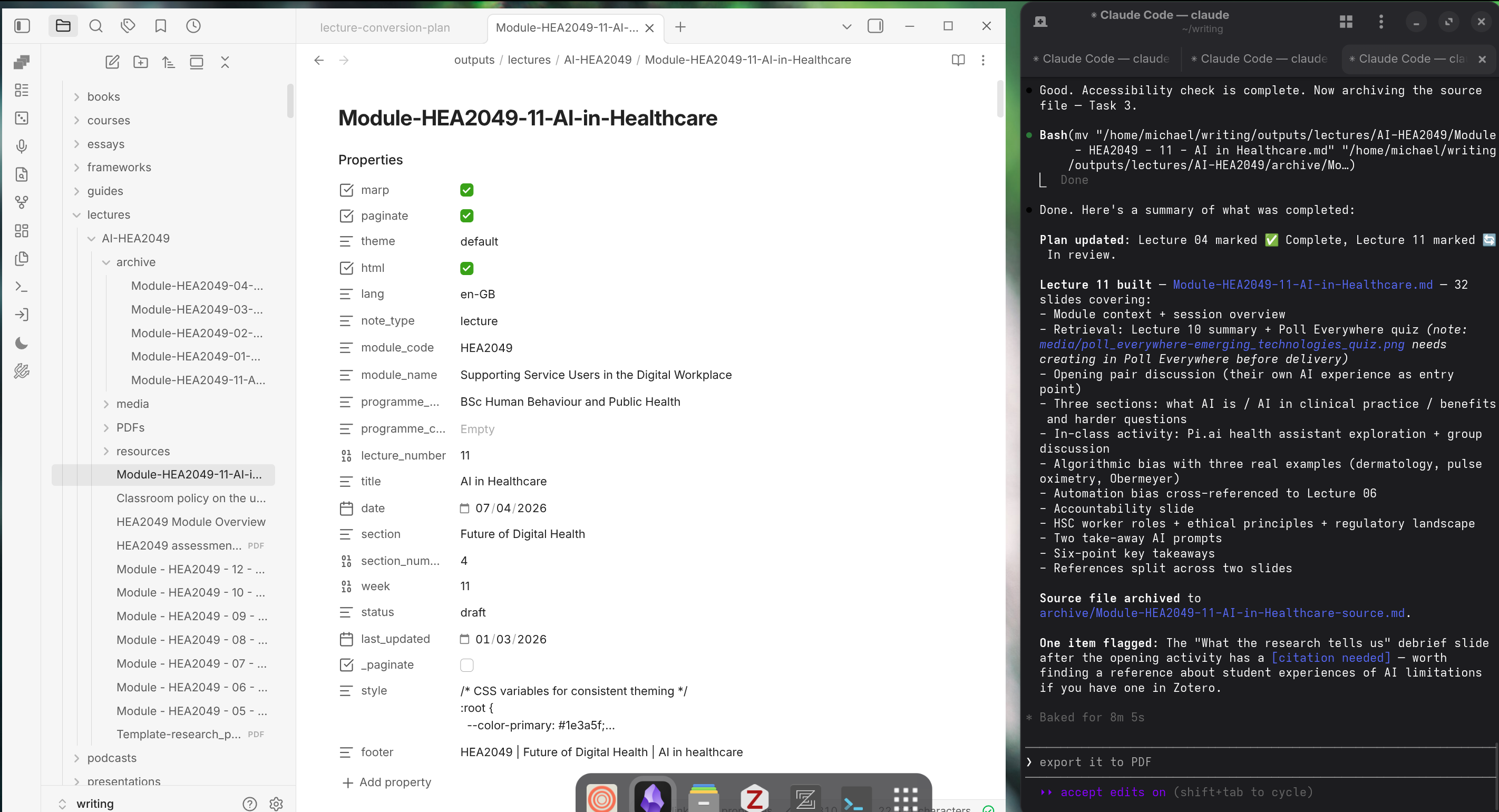 Thirty-two slides built, source file archived, and one item flagged: a debrief slide that needs a citation before delivery.
Thirty-two slides built, source file archived, and one item flagged: a debrief slide that needs a citation before delivery.
Thirty-two slides, four themes, an accessibility check against the persona’s tier framework — and one flag: a slide that makes a claim about what research shows, without a citation. The agent found it, noted it, and asked whether I had something in Zotero. I did, and it made the changes by adding the citation and reference list item.
Once the agent has completed all it’s tasks, the slides are ready for review, which I do using the slide preview with the Marp plugin in Obsidian.
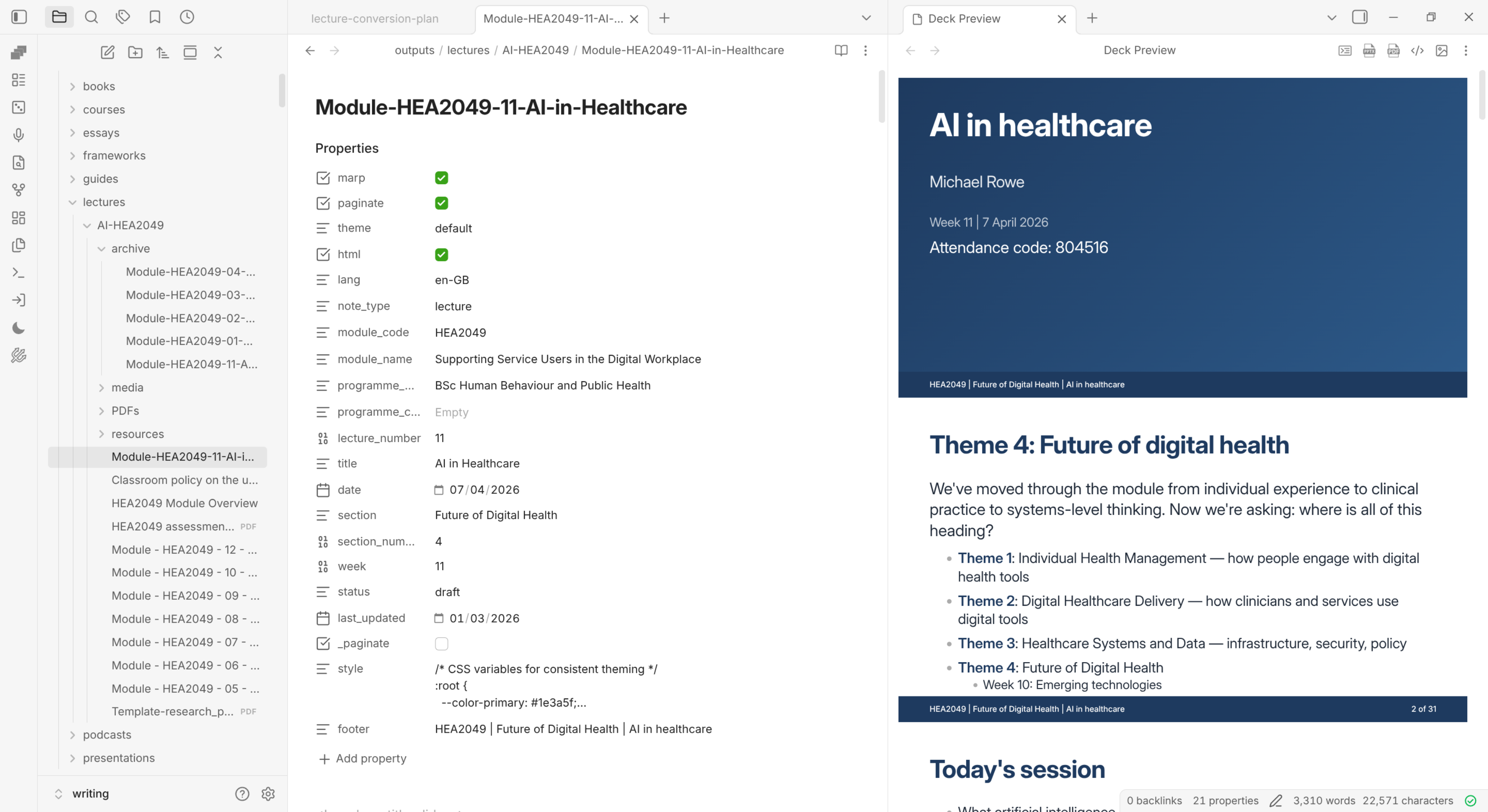 The output of the updated slides, including a new stylesheet and content aligned with the criteria defined by the personas. Formatting issues remain — font size, content fitting — but the structural work is done.
The output of the updated slides, including a new stylesheet and content aligned with the criteria defined by the personas. Formatting issues remain — font size, content fitting — but the structural work is done.
Working across a whole module
That was one file. For this module, I have twelve lectures for a semester-long module, each represented as a single markdown file in the same folder. When I ask a Claude Code to work on one of them, it also has access to all of them. It can read across the whole set, cross-reference content between sessions, look for inconsistencies, apply a change uniformly, or use external tools I’ve given it — all as part of the same task.
The flagged citation I pointed out earlier is a small example of a larger point. Checking every slide, across every lecture, for the kind of loose claims that accumulate when you’re writing quickly is uncomfortable work for a single person. It requires opening each file, reading carefully, and cross-checking across an entire module’s worth of material. It requires not deep expertise but sustained attention, which is exactly what makes it hard to do consistently. Agents working with well-defined personas can do it as a routine part of a build, not as a separate audit.
For example, these are the kinds of instructions you can provide to the model:
- “The NHS has just put out a position statement on the use of Copilot across the organisation (see attached). Review all lectures and identify specific sections where this point might add value.”
- “The HCPC has published a set of AI guidelines for allied health professionals. Summarise the guidance and suggest an insertion point across all 12 lectures.”
- “I’ve uploaded a new article on the concept of AI as a social determinant of health. Identify where this might be inserted across all my lectures, and add the article to the module reading list”
For each of the prompts above, I’d probably add something like the following: “Present your recommendations to me for confirmation. Don’t make any changes to the files yet.”
When I need to update all twelve lectures to reflect a change in the referencing convention, or apply a new footer template, or flag every slide that references a particular topic because the curriculum has been revised — the markdown lets me do that with a single agent instruction. The equivalent task with a folder of PowerPoint files would require opening each one individually in an application that the agent cannot see into.
The outputs are a by-product
The same source file can produce the formats that the rest of the world needs to interact with the content.
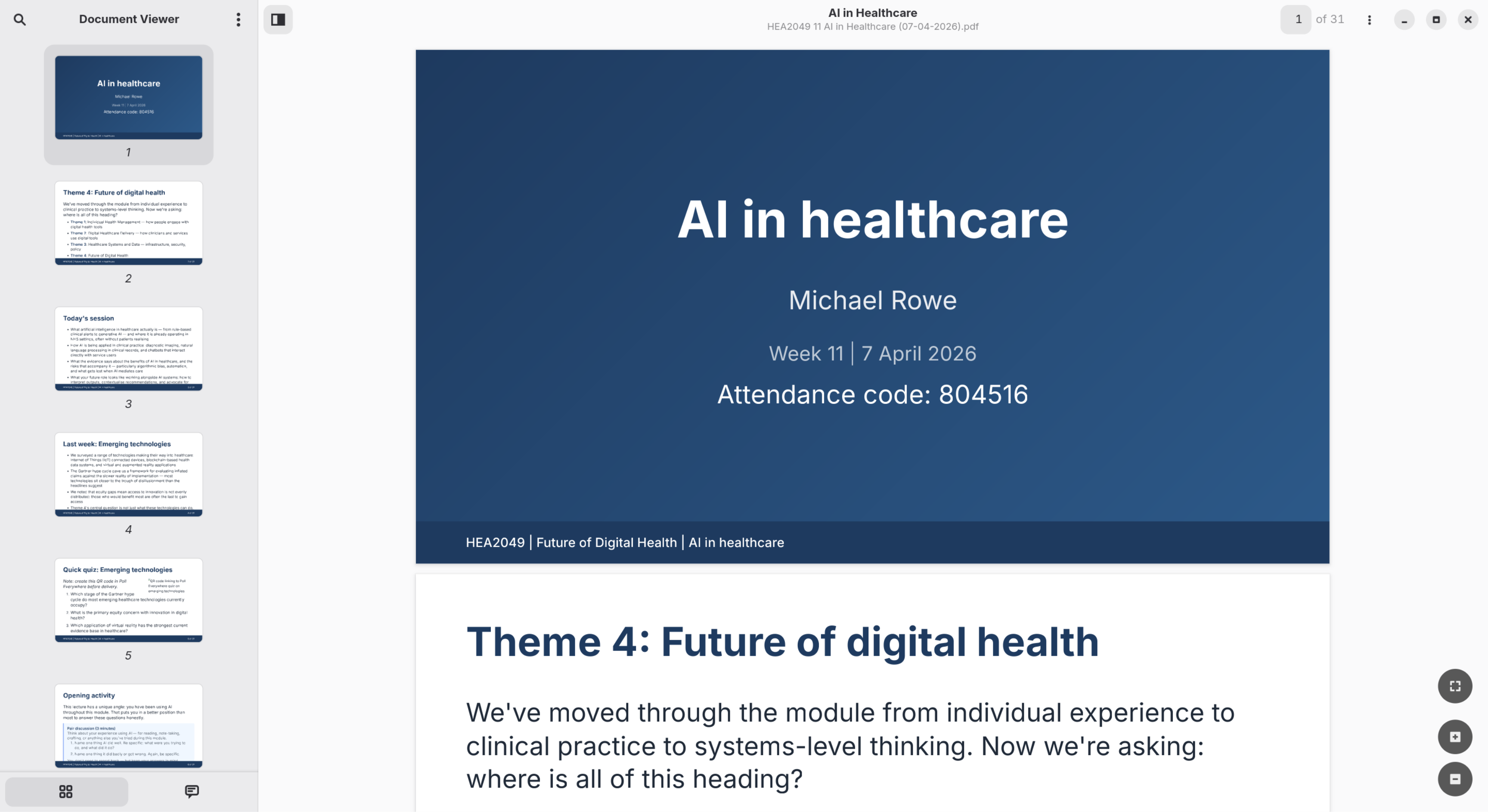 The Marp PDF export renders the markdown directly as formatted slides, preserving the structure and applying the theme.
The Marp PDF export renders the markdown directly as formatted slides, preserving the structure and applying the theme.
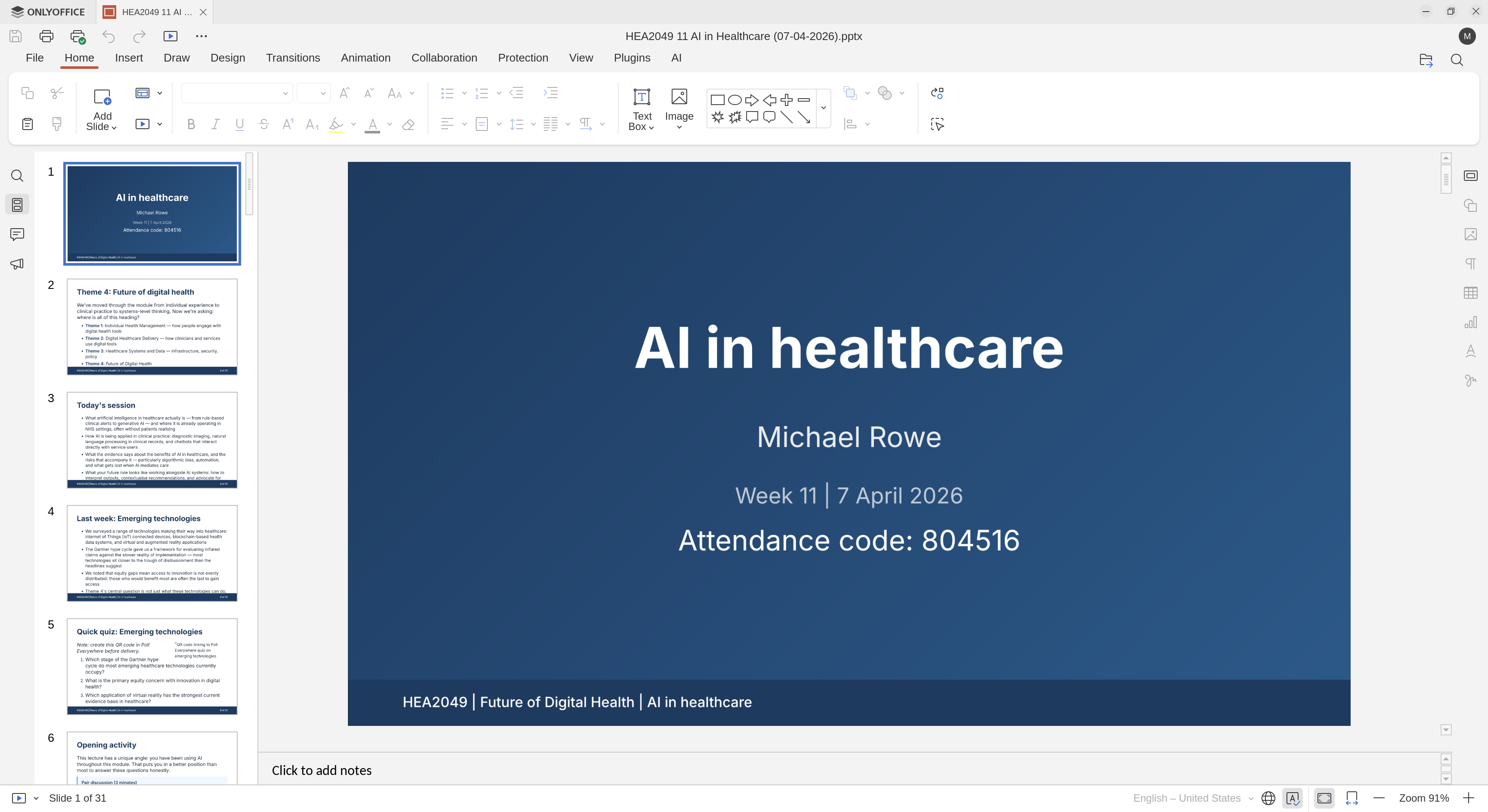 The same source exported as a
The same source exported as a .pptx — editable in PowerPoint or Impress for colleagues who need that format.
These outputs matter for practical reasons: a PDF goes to students, a PPTX goes to colleagues who need to edit or republish the material. But they are derivatives of the source, not the source itself. The PDF cannot be queried. The PPTX cannot be batch-processed by an agent looking for inconsistencies across twelve files. They are publication artefacts while the markdown files are the source.
Format as a structural decision
I’ve written elsewhere about building a knowledge base that AI can use, and about how decisions made years ago for unrelated reasons have turned out to matter considerably for agent-first workflows. Teaching materials in readable formats are a different version of the same pattern.
When content lives in a binary format (like PowerPoint or Openoffice, it’s locked to the applications that can open it. When it lives in a readable, structured format with consistent markdown and meaningful metadata, it becomes a substrate for anything: a version control system, a search tool, an AI agent. The structured properties visible in the screenshots above aren’t decorative. Module code, lecture number, section, status: each field is a dimension along which an agent can filter, query, or act. Ask it to export all draft lectures in section four of the module, or to identify every lecture that hasn’t been reviewed since a given date, and the metadata makes that possible. Without it, the agent is guessing.
This isn’t an argument for any particular tool. Obsidian, Marp, and a specific folder structure happen to be what I use. The point holds regardless: the format and structure your content lives in determines what can be done with it.
I started writing in markdown because I enjoyed it and that remains true. But the accumulated teaching materials across several years of modules now function as a working knowledge base in a way that the equivalent materials locked in PowerPoint files simply wouldn’t; not because of anything clever in the tooling, but because of what it means for content to be easily manipulable by AI agents.