Your research database is already AI-ready context
The most useful data for AI-assisted research isn’t in the cloud; it’s in the databases you’ve been building for years. Pointing an AI agent at your Zotero library shifts the available context from individual documents to your entire research history. The capability works. What breaks immediately is your metadata.
I’ve been using Claude Code to read files on my computer for a couple of months now; mostly PDFs, markdown notes, and text files. Point it at a document, ask it to analyse, summarise, or cross-reference against something I’m writing. Useful, but not particularly remarkable.
Then I realised something that should have been obvious: it can read any file I have local access to. Including databases.
Specifically, it can read my Zotero library. Not just the PDFs I’ve collected over the years, but the database file itself, at zotero.sqlite. The entire structure: metadata, tags, collections, notes, reading dates. Fifteen years of research decisions encoded in queryable form.
What it looks like in practice
I might be working on a draft piece of work about AI and assessment design. Instead of manually searching my Zotero library, selecting relevant papers, and then asking Claude to read those specific PDFs, I can prompt: “Read this draft section. Query my Zotero database to identify the most likely supporting evidence aligned with the claims I’m making.”
Prompt
The Zotero database is at ~/Zotero/zotero.sqlite — treat it as read-only. Here is a draft paragraph: [paste text]. Query the database for the most relevant items and return titles, authors, and any notes I’ve added.
Claude constructs the SQL queries, navigates the schema, and handles the structural complexity of the database. None of that requires my input. The agent queries the entire library at once. It knows what I have, when I saved it, how I tagged it, and what collections I’ve grouped it into. The available context for the AI agent expands from a single document to the entire research infrastructure.
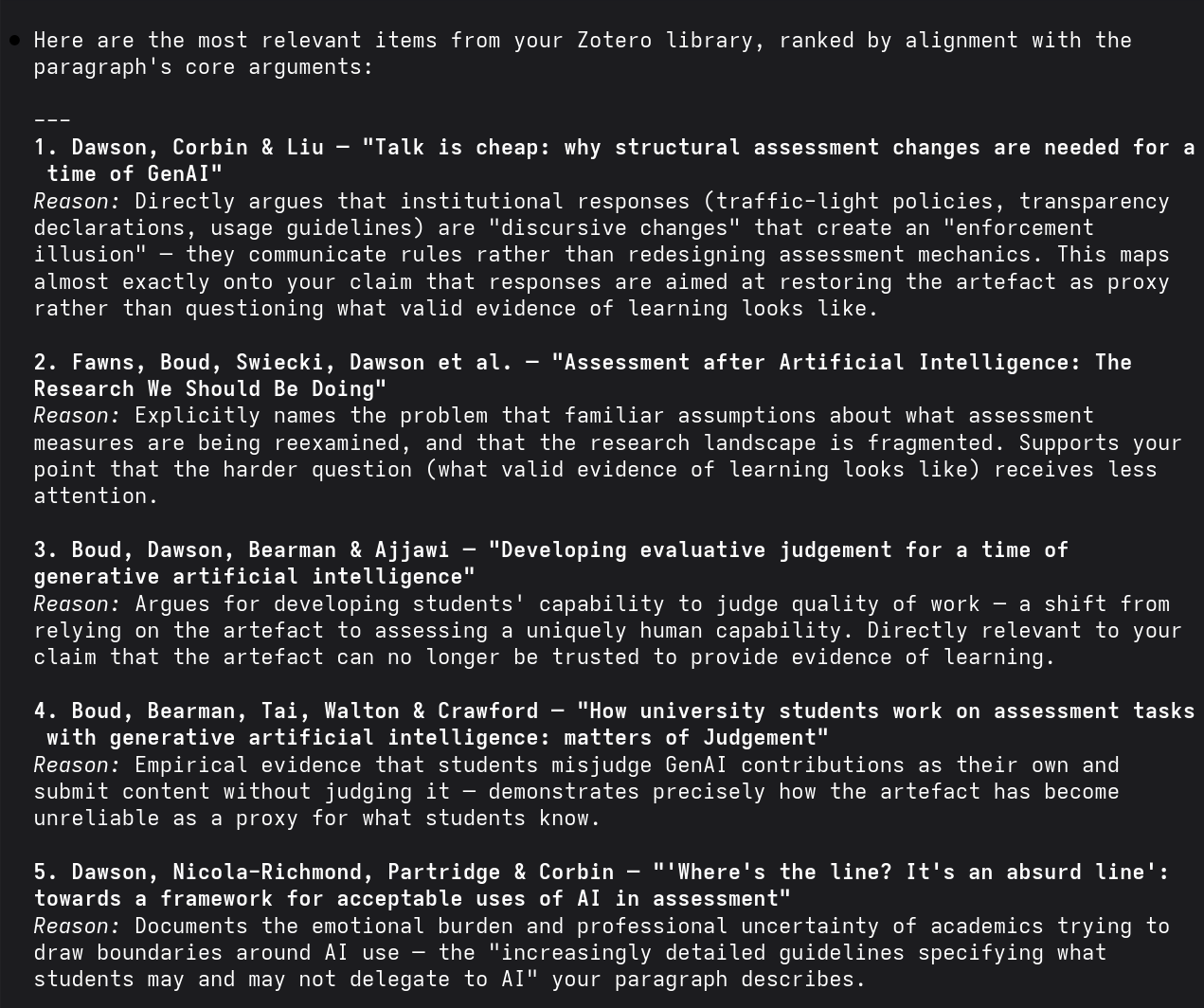
Claude Code querying a Zotero database and returning ranked references aligned with a draft paragraph about assessment design.
A caveat: direct database access isn’t the optimal approach for what I’m describing. Zotero offers access through its API (a structured interface designed for external tools), which is cleaner and safer, and I’ll write a separate post about using it to systematically tidy up my reference library. This post is a brief note documenting a proof of concept, not a recommendation.
What breaks
Access turns out to be the easy part. What Zotero revealed is a problem I hadn’t anticipated: AI agents can’t filter noise the way humans do. When Claude queries my library, it treats a poorly tagged conference abstract from 2011 with the same evidential weight as my core research from last month. Low-quality context isn’t just clutter. It actively degrades the quality of responses.
This makes metadata hygiene functionally critical. The “I’ll tag it properly later” habit, something I’m especially prone to, becomes expensive. Every piece of cruft in my reference library isn’t just something Claude scrolls past when searching; it gets retrieved and weighted as relevant evidence. What was invisible maintenance work becomes directly load-bearing for system performance.
The privacy trade-off is equally concrete. Every database query sends retrieved data to Claude’s servers for processing. My Zotero library contains my entire research history: what I’ve read, what I’ve considered worth keeping, what I’ve tagged as methodologically interesting versus theoretically important. The database stays local, but query results don’t. This isn’t hypothetical exposure; it’s the actual architecture of how local file access works with cloud-based language models.
What this means
Database access reveals the actual state of your data practices rather than the aspirational version. The system you imagine—clean tags, regular reviews, consistent metadata—meets the system you actually have. Accumulated cruft, deferred decisions, inconsistent naming conventions. What was previously invisible becomes measurable when an agent starts querying it for evidence.
The database lives on my filesystem. I control access, retention, structure, what gets tagged and how. The processing happens in Anthropic’s infrastructure, but the evidence base remains under my control in ways that fully cloud-based systems don’t offer. That matters, even if direct database access isn’t the long-term approach.
If you use a reference manager and an AI coding agent, the proof of concept is straightforward: point one at the other. What you learn about the state of your metadata will be more valuable than the queries themselves.